1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
| import pandas as pd
import plotly.graph_objects as go
def plot_balanced_sankey(
df: pd.DataFrame,
level_colors: dict[str, str] = None,
title: str = "收支流向图",
width: int = 800,
height: int = 800,
) -> None:
"""
绘制收支平衡的桑基图
参数:
df: 包含 source, target, value, level 的DataFrame
level_colors: 每个层级的颜色字典
title: 图表标题
width: 图表宽度
height: 图表高度
"""
node_values = {}
for idx, row in df.iterrows():
if row['source'] not in node_values:
node_values[row['source']] = {'out': 0, 'in': 0}
if row['target'] not in node_values:
node_values[row['target']] = {'out': 0, 'in': 0}
node_values[row['source']]['out'] += row['value']
node_values[row['target']]['in'] += row['value']
all_nodes = list(set(df['source'].unique()) | set(df['target'].unique()))
node_dict = {node: i for i, node in enumerate(all_nodes)}
total_value = df[df['source'] == '总额']['value'].sum()
node_labels = []
for node in all_nodes:
value = max(node_values[node]['in'], node_values[node]['out'])
percentage = value / total_value * 100
if node == '总额':
label = f"{node}\n{value:,.0f}M"
else:
label = f"{node}\n{value:,.0f}M\n({percentage:.1f}%)"
node_labels.append(label)
if level_colors is None:
level_colors = {
'L1': 'rgba(173, 216, 230, 0.7)',
'L2': 'rgba(135, 206, 235, 0.7)',
'L3': 'rgba(100, 149, 237, 0.7)',
'M': 'rgba(169, 169, 169, 0.7)',
'R1': 'rgba(144, 238, 144, 0.7)',
'R2': 'rgba(152, 251, 152, 0.7)',
'R3': 'rgba(143, 188, 143, 0.7)'
}
node_colors = []
for node in all_nodes:
level = df[(df['source'] == node) | (df['target'] == node)]['level'].iloc[0]
node_colors.append(level_colors[level])
link_colors = []
for _, row in df.iterrows():
source_level = df[(df['source'] == row['source']) |
(df['target'] == row['source'])]['level'].iloc[0]
if source_level.startswith('L'):
link_colors.append('rgba(173, 216, 230, 0.3)')
elif source_level.startswith('R'):
link_colors.append('rgba(144, 238, 144, 0.3)')
else:
link_colors.append('rgba(169, 169, 169, 0.3)')
fig = go.Figure(data=[go.Sankey(
node = dict(
pad = 20,
thickness = 25,
line = dict(color = "black", width = 0.5),
label = node_labels,
color = node_colors
),
link = dict(
source = [node_dict[src] for src in df['source']],
target = [node_dict[tgt] for tgt in df['target']],
value = df['value'],
color = link_colors
)
)])
fig.update_layout(
title = dict(
text = f"{title}<br><sub>单位:百万元</sub>",
font = dict(size=20),
x = 0.5,
y = 0.95
),
font = dict(size=12),
width = width,
height = height,
paper_bgcolor = 'rgba(0,0,0,0)',
plot_bgcolor = 'rgba(0,0,0,0)',
margin = dict(t=100, l=80, r=80, b=80)
)
fig.show()
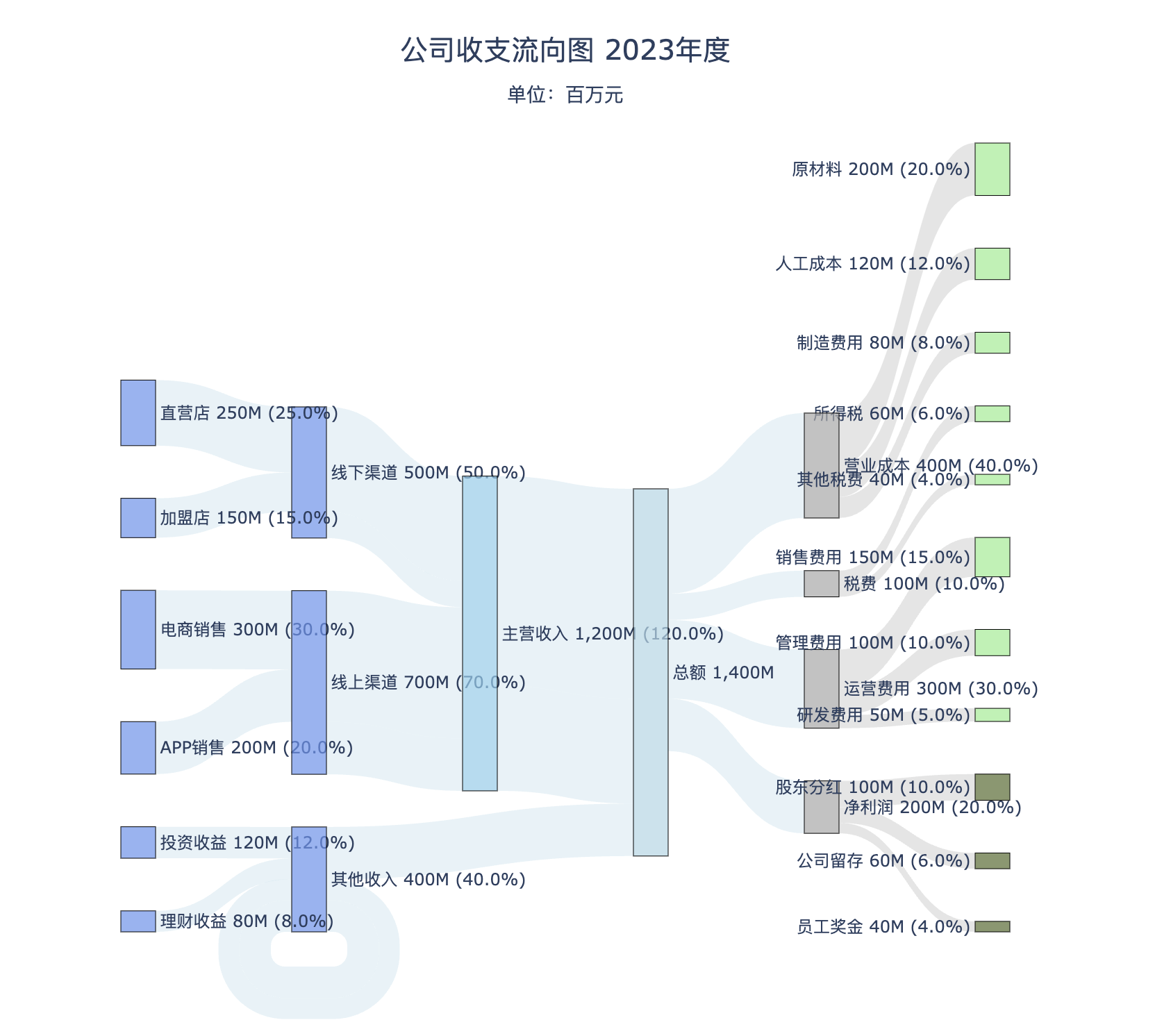
data = {
'source': [
'电商销售', 'APP销售',
'直营店', '加盟店',
'理财收益', '投资收益',
'线上渠道', '线上渠道',
'线下渠道', '线下渠道',
'其他收入', '其他收入',
'主营收入', '主营收入', '其他收入',
'总额', '总额', '总额', '总额',
'营业成本', '营业成本', '营业成本',
'运营费用', '运营费用', '运营费用',
'税费', '税费',
'净利润', '净利润', '净利润'
],
'target': [
'线上渠道', '线上渠道',
'线下渠道', '线下渠道',
'其他收入', '其他收入',
'主营收入', '主营收入',
'主营收入', '主营收入',
'其他收入', '其他收入',
'总额', '总额', '总额',
'营业成本', '运营费用', '税费', '净利润',
'原材料', '人工成本', '制造费用',
'销售费用', '管理费用', '研发费用',
'所得税', '其他税费',
'股东分红', '公司留存', '员工奖金'
],
'value': [
300, 200,
250, 150,
80, 120,
500, 200,
400, 100,
80, 120,
800, 400, 200,
400, 300, 100, 200,
200, 120, 80,
150, 100, 50,
60, 40,
100, 60, 40
],
'level': [
'L3', 'L3',
'L3', 'L3',
'L3', 'L3',
'L2', 'L2',
'L2', 'L2',
'L2', 'L2',
'L1', 'L1', 'L1',
'M', 'M', 'M', 'M',
'R1', 'R1', 'R1',
'R1', 'R1', 'R1',
'R1', 'R1',
'R2', 'R2', 'R2'
]
}
df = pd.DataFrame(data)
level_colors = {
'L3': 'rgba(100, 149, 237, 0.7)',
'L2': 'rgba(135, 206, 235, 0.7)',
'L1': 'rgba(173, 216, 230, 0.7)',
'M': 'rgba(169, 169, 169, 0.7)',
'R1': 'rgba(144, 238, 144, 0.7)',
'R2': 'rgba(85, 107, 47, 0.7)'
}
plot_balanced_sankey(
df=df,
level_colors=level_colors,
title="公司收支流向图 2023年度"
)
df = pd.DataFrame(data)
level_colors = {
'L1': 'rgba(173, 216, 230, 0.7)',
'L2': 'rgba(135, 206, 235, 0.7)',
'M': 'rgba(169, 169, 169, 0.7)',
'R1': 'rgba(144, 238, 144, 0.7)',
'R2': 'rgba(152, 251, 152, 0.7)',
}
plot_balanced_sankey(
df=df,
level_colors=level_colors,
title="公司收支流向图"
)
|